Estimating the number of people in a crowded environment is a central task in civilian surveillance. Most vision-based counting techniques depend on detecting individuals in order to count, an unrealistic proposition in crowded settings. It is possible to count people in crowds without explicitly detecting persons in each image frame?
The answer is yes. In this system, groups of image sensors segment foreground objects from the background, aggregate the resulting silhouettes over a network, and compute a planar projection of the scene’s visual hull. A geometric algorithm then calculates bounds on the number of persons in each region of the projection, after phantom regions have been eliminated. The computational requirements scale well with the number of sensors and the number of people, and only limited amounts of data are transmitted over the network.
Here is an example of the system in operation. Seven cameras are used to count and track people in a cluttered setting. Only silhouette (binary) information is used from each camera after background subtraction. The vertical lines are the boundaries of the estimated objects. The height of each horizontal bar represents the computed distance of each object from the camera. An 8th camera view was not used in the computation and served as the ground truth and to capture the video.
The next video is the “radar view” of the same experiment (action starts at time 0:20). The view shows the estimated bounds on the object locations and their counts.
The approach is described in the paper Counting People in Crowds with a Real-Time Network of Simple Image Sensors (Ninth IEEE International Conference on Computer Vision, 2003) and US patent 6,987,885.
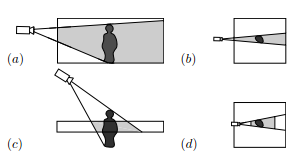
People often walk along a flat surfaces and the projection of the scene visual hull onto this plane contains the most useful information for counting and bounding the location of people. The figure on the left shows how this projection is computed. A measured silhouette at each camera sweeps a cone in 3-D space which is flattened onto a plane. The side view of a camera looking at a person is depicted in (a). The shaded region is a cross-section of the 3-D cone formed by the silhouette of the person. This cone is projected onto the plane as seen from the top in (b). The shaded area in (b) represents the projected visual hull from one camera. (c) and (d) show the projection for a camera not oriented horizontally.
The planar projection of the visual hull is the intersection of the projected silhouette cones from all cameras. Note that we project the silhouette cones and then intersect them in 2-D. This is not exactly equal to first computing the 3-D visual hull and then projecting the result. But in this problem both are close to equal and the proposed approach is much cheaper to compute.
The polygons composing the projected visual hull represent all possible plane that may contain an object.  But the projected visual hull is ambiguous, because several arrangements of objects can be consistent with a given visual hull (right figure). Some of the polygons in the projection can thus be empty. The key of the approach is to keep track of the lower and upper bounds for the number of objects in each polygon by assuming continuity of motion. A History Tree is used to track these bounds through time and whenever these bounds converge for a polygon an exact count becomes known for that polygon.
But the projected visual hull is ambiguous, because several arrangements of objects can be consistent with a given visual hull (right figure). Some of the polygons in the projection can thus be empty. The key of the approach is to keep track of the lower and upper bounds for the number of objects in each polygon by assuming continuity of motion. A History Tree is used to track these bounds through time and whenever these bounds converge for a polygon an exact count becomes known for that polygon.
